
【ネットワーク】OSI参照モデルを理解するために図解してみた
takahide
初心者がITを楽しむブログ

おはようございます。タカヒデです。
早速ですが「検索エンジンのアルゴリズム」ってどのようにして作られているのか気になりませんか?
Googleで調べ物をしたいとき、入力したキーワードから検索結果が表示される。
そして数あるWebページからなぜそのページが選ばれるのか。
本日はそんな「検索エンジンのアルゴリズム」がどのようにしてできているのかを紐解いていく記事です。
なお、本日の内容は「世界でもっとも強力な9のアルゴリズム」という本から引用させていただいています。
2012年に発売された本ですが、様々なアルゴリズムを分かりやすく教えているのでオススメですよ。

なお、現在の検索アルゴリズムは今回紹介する内容よりも、もっと複雑な要素が絡み合って作られています。
そのため、今回紹介するアルゴリズムは「元々はこんなものだったみたいだよー」と思っていただければ幸いです。
「検索エンジン」皆さんもよく使いますよね。
GoogleとかYahoo!とかでつかうアレです。
我々の生活には欠かせないものになっていますね。
この検索エンジンは、「マッチング」と「ランキング」という2つのアルゴリズムによって成り立っています。
まず、「マッチング」によりキーワードにマッチしたページを選び、その中から「ランキング」により関連度順に並び替えます。
関連度が高いWebページほど、検索時に上位に表示されるわけですね。
ではここからは「マッチング」「ランキング」それぞれのアルゴリズムを詳しく見てみましょう。
まずは「マッチング」のアルゴリズムから見ていきましょう。
これは先ほどもお伝えした通り、「膨大な量のWebページの中からキーワードにマッチしたページを選ぶ」作業です。
マッチングには「インデックス」という概念が使われます。
「インデックス」とは「索引」とも呼ばれ、本の最後に「Python – 130」のように「その単語が書かれたページ数」が分かります。
これをWebページで考えてみましょう。
下記の超簡単な3つのWebページがあったとします。
Pythonは初心者にも人気のプログラミング言語です。
データ分析、AI開発など幅広く使われています。
カレーは定番の家庭料理です。
野菜や肉を使って作ります。
ヘビは英語でPythonと書きます。
爬虫類の動物です。
これらのページのテキストを単語に切り分け、出てくる順番に番号を振りましょう。
すると、位置情報(単語がどのページで何番目の単語として出てくるのか)が付与されたインデックスを作ることができます。
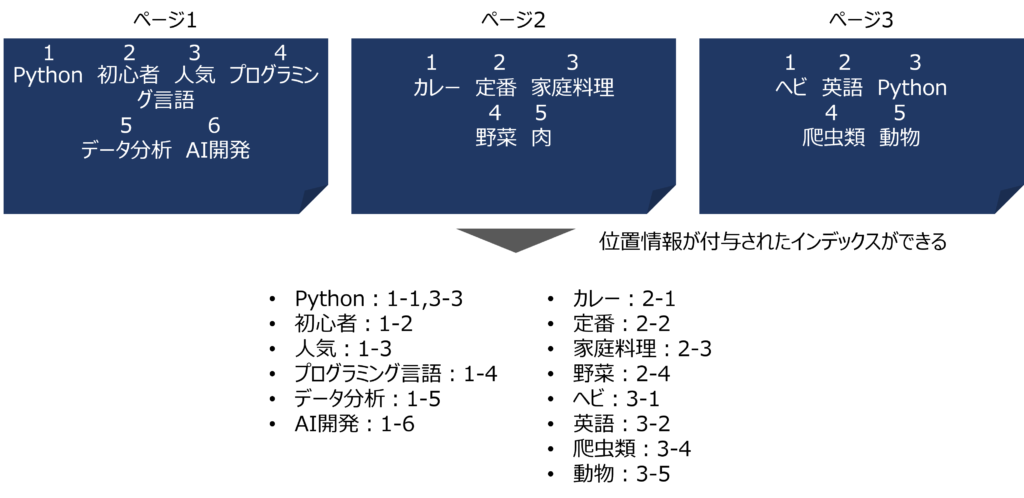
これにより、「カレー」と調べたらページ2がマッチングされ、「Python」と調べたら、ページ1とページ3をマッチングすることができます。
さらには同じ「Python」でも「Python プログラミング言語」ならページ1、「Python 動物」ならページ3と、関連キーワードの位置情報の近さで把握することができます。
このようにインデックスを駆使することによってキーワードにマッチしたWebページを見つけ出しているわけですね。
続けてランキングのアルゴリズムを見ていきましょう。
ここで知りたいこと検索エンジンで「Python プログラミング」と調べて上位に出てくるものをどのように判断するか?ということです。
先に結論から、かつてのランキングアルゴリズムを端的に表すと「みんなからリンクされているWebページは上位になるよー」って感じです。
リンクというのは「ボタンを押したらそのWebページに飛ぶやつ」のことですね。
さて質問です。
どちらが権威性が高いと思いますか?
当然ですがBのサム・アルトマンのWebページです。
ではこの権威性の高さを機械はどのように判断するのでしょうか?
それはリンクの数で判断します。
リンクがたくさんついているWebページは上位。
リンクがたくさんついているWebページからのリンクはさらに上位。
イメージにするとこんな感じです↓
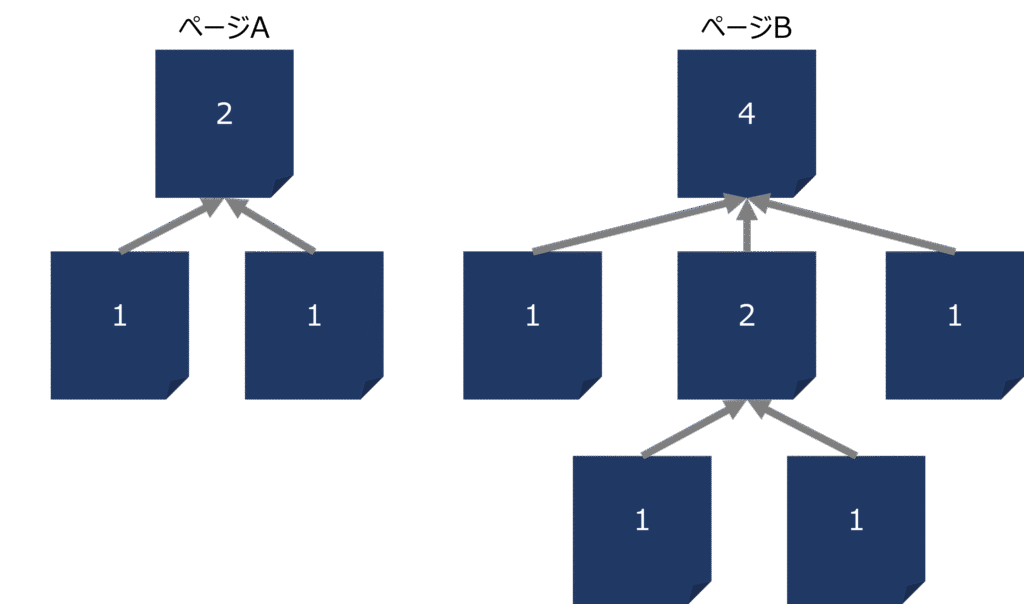
既にリンクがついている人からのリンクの方が権威性が高いため、ページBの方が権威性が高いということが分かります。
ただ、このランキングアルゴリズムには問題があり、「リンクが無限につながり、元をたどろうとしたらぐるぐる回ってしまう」ということが起きかねません。
それを解消するために、ランダムに全く別のWebページを選んだり、一定確率でリンクをたどることを辞めたりする「ランダムサーファーモデル」というアルゴリズムが採用されています。

以上がランキングアルゴリズムでした。
なお、現在の検索アルゴリズムが今回紹介したものをそのまま使用しているわけではありません。
先ほどのリンクによる権威性も自動でリンクを大量作成して悪用することもできてしまうわけです。
そうならないために、このアルゴリズムをより簡単にできるようにしていたり、他のアルゴリズムを駆使してページランキングをきめています。
「かつてこれらのアルゴリズムをベースに作られていたんだなー」くらいで思っていただけると良いと思います。
以上が「検索エンジンのアルゴリズム」がどのようにしてできているのかを紐解いていく記事でした。
少しは「検索アルゴリズム」の中身が理解できましたか?
なにか勉強になったと思っていただけたら幸いです。
お疲れさまでした。



