WindowsタスクスケジューラでPythonアプリの起動ができなかったので対処を記録する
takahide
初心者がITを楽しむブログ

おはようございます。タカヒデです。
「Pythonで業務の自動化」よく聞くキーワードですね。
私もこれをやっていきたいと思います。
「どんなことやろうかな?」と思ったのですが、せっかくなのでなるべく業務で使えるものにしたい…
ということで「複数のCSVを1つのExcelにまとめる」という作業を自動化していきます。
具体的には、「毎月の明細データをボタン一つでExcelに積み上げていく」という作業です。
同じように業務自動化を検討されている方は参考にしてください。
ではまず今回自動化する作業の完成イメージから見ていきましょう。
やりたいことは、「複数のCSVを1つのExcelにまとめる」という作業を自動化することです。
以下の3か月分の明細データがあります。
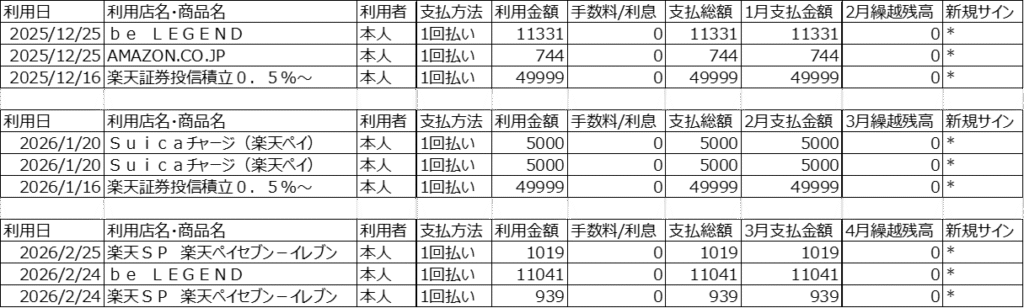
これを以下のように1つのExcelとしてデータを積み上げていきます。

もちろんコピペをすれば誰でもできます。
しかし、今回は「自動化」なので、ボタン一つで作業が完了することを目指していきます。
まずは実際にコードを書き始める前に今回の作業を分解して整理します。
今回でいうと、このなかで②~⑥の作業を自動化します。
つまり私たちが手動で行うのは①と⑦のみとなります。
続けて、どのようなフォルダ構成にするか考えます。
今回は以下の構成にしてみました。
05_python_credit_card_auto/
├ data/ ⇐CSVデータを格納するフォルダ
│ ├ enavi202601.csv
│ ├ enavi202602.csv
│ └ enavi202603.csv
├ output/
│ └ marge.xlsx ⇐データを積み上げたExcel
├ merge_csv.py ⇐自動化のコードが書かれたPython
└ 実行.bat ⇐実行ボタン
毎月の所作としては、「dataフォルダ」に明細データを確認し、「実行.bat」を実行するだけのイメージです。
今回使うPythonのライブラリは以下の2つです。
どちらも事前にターミナルでインストールしておきましょう。
pip install pandas openpyxlようやくPythonで自動化のコードを記載していきます。
「dataフォルダ」と同階層に「merge_csv.py」を作成し、以下のコードを記載しましょう。
import pandas as pd
from pathlib import Path
# フォルダの設定
BASE_DIR = Path(__file__).resolve().parent
DATA_DIR = BASE_DIR / "data"
# 出力先の設定
OUTPUT_DIR = BASE_DIR / "output"
OUTPUT_FILE = OUTPUT_DIR / "merge.xlsx"
# フォルダが無ければ作成
OUTPUT_DIR.mkdir(exist_ok=True)
# dataフォルダ内のCSVファイルを取得
csv_files = list(DATA_DIR.glob("*.csv"))
# 「merge.xlsx」が存在するかを確認
if OUTPUT_FILE.exists():
existing_df = pd.read_excel(OUTPUT_FILE)
imported_files = set(existing_df["取込元ファイル"].unique())
else:
existing_df = pd.DataFrame()
imported_files = set()
# 結合用リスト
df_list = []
# CSVファイルの読み込み
for file in csv_files:
# 過去に取込済であればスキップ
if file.name in imported_files:
print(f"{file.name}は取込済です")
continue
df = pd.read_csv(file, encoding="utf-8-sig")
# 列名の変更ルールを格納
rename_columns = {}
# 列名を確認
for column in df.columns:
if "支払金額" in column:
rename_columns[column] = "当月支払金額"
if "繰越残高" in column:
rename_columns[column] = "繰越残高"
# 列名を変更
df = df.rename(columns=rename_columns)
# 取り込み元となるファイル名を列に追加
df["取込元ファイル"] = file.name
# 結合用リストに追加
df_list.append(df)
# 新たなファイルがある場合だけCSVを結合
if df_list:
new_df = pd.concat(df_list, ignore_index=True)
if existing_df.empty:
merged_df = new_df
else:
merged_df = pd.concat([existing_df, new_df], ignore_index=True)
# Excelに出力
merged_df.to_excel(OUTPUT_FILE, index=False)
print("Excel出力完了", OUTPUT_FILE)
else:
print("新たなファイルはありません")
ここで行っている大まかな流れは以下です。
実際にやっていることはコードを見ていただければと思いますが、ポイントとして2点紹介します。
元の明細データを見ていただければ分かりますが、月によってカラム名が異なります。
「1月支払金額」「2月繰越残高」の2か所です。
そこで、以下のコードを追加しています。
# 列名を確認
for column in df.columns:
if "支払金額" in column:
rename_columns[column] = "当月支払金額"
if "繰越残高" in column:
rename_columns[column] = "繰越残高"
# 列名を変更
df = df.rename(columns=rename_columns)これによって、
に変更することで、カラム名を統一しています。
基本的に明細データを積み上げているだけなので、どのファイルから拾ってきたデータなのかを追加する必要はありません。
しかし、元のデータを追いかけられるよう、「取込元ファイル」というカラムを追加しています。
# 取り込み元となるファイル名を列に追加
df["取込元ファイル"] = file.nameこれによって、各レコードに取込元となるCSVファイル名が追加されるようになっています。
最期にボタン一つで動作するよう「.bat」ファイルを作ります。
「.bat」ファイルではWindowsでコマンドを実行することができます。
もしMacやLinuxの場合は「.sh」ファイルで、同じようなことができるはずです。
「merge_csv.py」と同じフォルダ内に「実行.bat」を作成しましょう。
そして、「実行.bat」に以下のコードを記載します。
@echo off
cd /d C:\programming\05_python_credit_card_auto
python merge_csv.py
pause「cd /d」以降はご自身の作業をしていたフォルダを参照させてください。
これで「毎月の明細データを1つのExcelに積み上げていく」という作業の自動化の完成です。
最期に、正しく自動化できるか、実際に実行してみましょう。
現在のファイル構成は以下です。
「実行.bat」を実行してみましょう。

「Excel出力完了」と出ます。
「outputファイル」が新たに作成されていることが分かります。

「merge.xlsx」を開くと、3か月分の明細データが蓄積されていることが分かります。

正しくできましたね。
誰かの参考になれば幸いです。
お疲れさまでした。






